Network Processors: Programmable Technology for Building Network Systems
Автор: Douglas Comer
Источник: The Internet Protocol Journal - Volume 7, Number 4
Автор: Douglas Comer
Источник: The Internet Protocol Journal - Volume 7, Number 4
Chip vendors have defined a new technology that can be used to implement packet-processing systems such as routers, switches, and firewalls. The technology offers the advantages of being software-programmable and sufficiently high-speed to accommodate interfaces running at 10 Gbps.
This article provides an overview of the technology, describes the motivations, and presents a brief survey of hardware architectures. It also discusses the relationship between programming and the underlying hardware.
A wide variety of packet-processing systems are used in the Internet, including DSL modems, Ethernet switches, IP routers, Network Address Translation (NAT) boxes, Intrusion Detection Systems (IDS), Softswitches used for Voice over IP (VoIP), and security firewalls. Such systems are engineered to provide maximal functionality and performance (for example, operate at wire speed) while meeting constraints on size, cost, and time to market.
Engineers who design network systems face the additional challenges of keeping designs scalable, general, and flexible. In particular, because industry trends change rapidly, typical engineering efforts must accommodate changes in requirements during product construction and changes in the specification for a next-generation product.
During the past 20 years, engineering of network systems has changed dramatically. Architectures can be divided broadly into three
generations:
The change from a centralized to a completely distributed architecture has been fundamental because it introduces additional complexity. For example, in a third-generation IP router, where each network interface has a copy of the routing table, changing routes is difficult because all copies must be coordinated to ensure correctness and the router should not stop processing packets while changes are propagated.
Although the demand for speed pushed engineers to use ASIC hardware in third-generation designs, the results were disappointing. First, building an ASIC costs approximately US$1 million. Second, it takes 18 to 22 months to generate a working ASIC chip. Third, although engineers can use software simulators to test ASIC designs before chips are manufactured, networking tasks are so complex that simulators cannot handle the thousands of packet sequences needed to verify the functionality. Fourth, and most important, ASICs are inflexible.
The inflexibility of ASICs impacts network systems design in two ways. First, changes during construction can cause substantial delay because a small change in requirements can require massive changes in the chip layout. Second, adapting an ASIC for use in another product or the next version of the current project can introduce high cost and long delays. Typically, a silicon respin takes an additional 18 to 20 months.
In the late 1990s as demand for rapid changes in network systems increased, chip manufacturers began to explore a new approach: programmable processors designed specifically for packet-processing tasks. The goal was clear: combine the advantage of software programmability, the hallmark of the first-generation network systems, with high speed, the hallmark of third-generation network systems.
Chip vendors named the new technology network processors, and predicted that in the future, most network systems would be constructed using network processors. Of course, before the prediction could come true, vendors faced a tough challenge: programming introduces an extra level of indirection, meaning that functionality implemented directly in hardware always performs faster than the same functionality implemented with software. Thus, to make a network processor fast enough, packet-processing tasks need to be identified and special-purpose hardware units constructed to handle the most intensive tasks.
Interestingly, vendors also face an economic challenge: although an ASIC costs a million dollars to produce, subsequent copies of the chip can be manufactured at very low cost. Thus, the initial development cost can be amortized over many copies. In contrast, purchasing conventional processors does not entail any initial development cost, but vendors typically charge at least an order of magnitude more per unit than for copies of an ASIC. So, vendors must consider a pricing strategy that entices systems builders to use network processors in systems that have many network interfaces with multiple processors per interface.
As vendors began to create network processors, fundamental questions arose. What are the most important protocol-processing tasks to optimize? What hardware units should a network processor provide to increase performance? What I/O interfaces are needed? What sizes of instruction store and data store are needed? What memory technologies should be used (for example, Static Random-Access Memory [SRAM], Dynamic Random-Access Memory [DRAM], or others)? How should functional units on the network-processor chip be organized and interconnected (for example, what on-chip bus infrastructure should be used)?
Interestingly, although they realized that it was essential to identify the basic protocol-processing tasks before hardware could be built to handle those tasks efficiently, chip vendors had little help from the research community. Much effort had been expended considering how to implement specific protocols such as IP or TCP on conventional processors. However, researchers had not considered building blocks that worked across all types of network systems and all layers of the protocol stack. Consequently, in addition to designing network-processor chips, vendors needed to decide which protocol functions to embed in hardware, which to make programmable, and which (if any) to leave for special-purpose interface chips or coprocessors. Finally, chip vendors needed to choose software support including programming language(s), compilers, assemblers, linkers, loaders, libraries, and reference implementations.
Faced with a myriad of questions and possibilities about how to design network processors and the recognition that potential revenue was high if a design became successful, chip vendors reacted in the expected way: each vendor generated a design and presented it to the engineering community. By January 2003, more than 30 chip vendors sold products under the label "network processor."
Unfortunately, the euphoria did not last, and many designs did not receive wide acceptance. Thus, companies began to withdraw from the network-processor market, and by January 2004, fewer than 30 companies sold network processors.
Hardware engineers use three basic techniques to achieve high-speed processing: a single processor with a fast clock rate, parallel processors, and hardware pipelining. Figure 1 illustrates packet flow through a single processor, which is known as an embedded processor architecture or a run-to-completion model. In the figure, three functions must be performed on each packet.

Figure 1: Embedded Processor Architecture in Which a Single Processor Handles All Packets
Figure 2 illustrates packet flow through an architecture that uses a parallel approach. A coordination mechanism on the ingress side chooses which packets are sent to which processor. Coordination hardware can use a simplistic round-robin approach in which a processor receives every Nth packet, or a sophisticated approach in which a processor receives a packet whenever the processor becomes idle.

Figure 2: Parallel Architecture in Which the Incoming Packet Flow Is Divided Among Multiple Processors
Figure 3 illustrates packet flow through a pipeline architecture. Each packet flows through the entire pipeline, and a given stage of the pipeline performs part of the required processing.

Figure 3: Pipeline Architecture in Which Each Incoming Packet Flows Through Multiple Stages of a Pipeline
As we will see, pipelining and parallelism can be combined to produce hybrid designs. For example, it is possible to have a pipeline in which each individual stage is implemented by parallel processors or a parallel architecture in which each parallel unit is implemented with a pipeline.
To appreciate the broad range of network-processor architectures, we will examine a few commercial examples. Commercial network processors first emerged in the late 1990s, and were used in products as early as 2000. The examples contained in this article are chosen to illustrate concepts and show broad categories, not to endorse particular vendors or products. Thus, the examples are not necessarily the best, nor the most current.
The first example, from Alchemy Semiconductor (now owned by Advanced Micro Devices), illustrates an embedded processor augmented with special instructions and I/O interfaces.
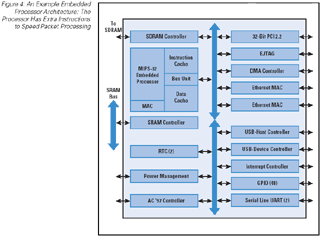
Figure 4: An Example Embedded Processor Architecture: The Processor Has Extra Instructions to Speed Packet Processing
A network processor from AMCC uses an architecture with parallel processors plus coprocessors that handle packet-processing tasks. When a packet arrives, one of the parallel processors, called cores, handles the packet. The coprocessors are shared—any of the parallel processors can invoke a coprocessor, when needed.
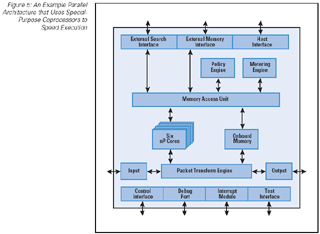
Figure 5: An Example Parallel Architecture that Uses Special-Purpose Coprocessors to Speed Execution
A network processor (named Rainier) originally developed by IBM and now owned by Hifn Corporation uses a parallel architecture, and includes a variety of special-purpose and general-purpose processors. For example, the chip provides parallel ingress and egress hardware to handle multiple high-speed network interfaces. It also has intelligent queuemanagement hardware that enqueues incoming packets in an ingress data store, a switching fabric interface built onto the chip, and an intelligent egress data store. Figure 6 illustrates the overall architecture of the Hifn chip.

Figure 6: An Example Parallel Architecture that Includes Hardware Support for Ingress and Egress Processing as well as Intelligent Queuing
The Embedded Processor Complex (EPC) on the Hifn chip contains 16 programmable packet processors, called picoengines, as well as various other coprocessors. In addition, the EPC contains an embedded PowerPC to handle control and management tasks. Figure 7 shows a few of the many processors in the EPC.

Figure 7: Structure of the Embedded Processor Complex on the Example Network Processor in Figure 6
Although it is not a chip vendor, Cisco Systems uses network processors in its products, and has developed network processors for internal use. One of the more interesting designs employs parallel pipelines of homogeneous processors. Figure 8 illustrates the architecture of the Cisco chip. When a packet enters, the hardware selects one of the pipelines, and the packet travels through the entire pipeline.

Figure 8: an Example Architecture that Uses Parallel Pipelines of Homogeneous Processors
EZchip Corporation sells a network processor that combines pipelining and parallelism by using a four-stage pipeline in which each stage is implemented by parallel processors. However, instead of using the same processor type at each stage, the EZchip architecture employs heterogeneous processors, with the processor type at each stage optimized for a certain task (for example, the processor that runs forwarding code is optimized for table lookup). Figure 9 illustrates the architecture.

Figure 9: An Example Architecture that Uses a Pipeline of Parallel Stages with Heterogeneous Processors
Xelerated Corporation sells an interesting network processor that uses a pipelining approach. Unlike other network processors, the Xelerated chip uses an extremely long pipeline of 200 stages. Figure 10 illustrates the overall architecture. To achieve high speed, each stage is limited to executing four instructions per packet.

Figure 10: An Example of an Extremely Long Pipeline with 200 Stages
In fact, the Xelerated architecture is more complex than the figure shows because the pipeline contains special hardware units after every 10 stages that allow external communication (for example, access to external memory or a call to a coprocessor).
The previous survey is not meant to be complete. Two notable network processors have been omitted. Agere Systems and Intel each manufacture a network processor. Agere's design consists of a short pipeline that has two basic stages. Agere's architecture is both interesting and unusual because the two stages are composed of unconventional processors. For example, the processor used for classification performs high-speed pattern matching, but does not have conventional instructions for iteration or conditional testing. For details about the Agere network processor see [1], which includes the source code for an example Differentiated Services (DiffServ) network system.
Intel's chip uses a parallel approach in which a set of microengines are programmed to handle packets. The Intel hardware allows a programmer to pass packets between microengines, meaning a programmer can decide to arrange microengines in a software pipeline. For details about the Intel network processor see [2], which includes the source code for an example NAT implementation.
Although the general idea of building programmable devices seems appealing, most network-processor designs make programming difficult. In particular, to achieve high speed, many designs use low-level hardware constructs and require a programmer to accommodate the hardware by writing low-level code. Many network processors are much closer to a microcontroller than a conventional processor, and are programmed in microassembly language. Programmers must be conscious of details such as register banks.
Programming is especially difficult in cases where the network-processor hardware uses explicit parallelism and requires a programmer to plan program execution in such a way that processors do not contend for resources simultaneously or otherwise stall. For example, on one vendor's chip, a packet processor can execute several hundred instructions while waiting for a single memory access to complete. Thus, to achieve high performance, a programmer must start a memory operation, go on with other calculations while the memory operation proceeds, and then check that the operation has completed.
In addition to considering processing, some network processors provide a set of memory technologies, and require a programmer to allocate each data item to a specific memory. A programmer must understand memory latency, the expected lifetime of a data object, and the expected frequency of access as well as properties of the hardware such as memory banks and interleaving.
A few pleasant exceptions exist. For example, Agere Systems provides special-purpose, high-level programming languages to program its network processors. Thus, it is easy to write classification code or trafficmanagement scripts for an Agere processor. More important, an Agere chip offers implicit parallelism: a programmer writes code as if a single processor is executing the program; the hardware automatically runs multiple copies on parallel hardware units and handles all details of coordination and synchronization.
Another pleasant exception comes from IP Fabrics, which has focused on building tools to simplify programming. Like Agere, IP Fabrics has developed a high-level language that allows a programmer to specify packet classification and the subsequent actions to be taken. The language from IP Fabrics is even more compact than the language from Agere.
To provide maximal flexibility, ease of change, and rapid development for network systems, chip vendors have defined a new technology known as network processors. The goal is to create chips for packet processing that combine the flexibility of programmable processors with the high speed of ASICs.
Because there is no consensus on which packet-processing functions are needed or which hardware architecture(s) are best, vendors have created many architectural experiments. The basic approaches comprise an embedded processor, parallelism, and hardware pipelining. Commercial chips often combine more than one approach (for example, a pipeline of parallel stages or parallel pipelines).
Programming network processors can be difficult because many network processors provide low-level hardware that requires a programmer to use a microassembly language and handle processor, memory, and parallelism details. A few exceptions exist where a vendor provides a high-level language.
[1] Comer, D., Network Systems Design Using Network Processors, Agere Version, Prentice Hall, 2005.
[2] Comer, D., Network Systems Design Using Network Processors, Intel 2xxx Version, Prentice Hall, 2005.
This article is based on material in Network Systems Design Using Network Processors, Agere Version, and Network Systems Design Using Network Processors, Intel 2xxx Version by Doug Comer. Both books are published by Prentice Hall in 2005. Used with permission.
DOUGLAS E. COMER is a Visiting Faculty at Cisco Systems, a Distinguished Professor of Computer Science at Purdue University, a Fellow of the ACM, and editor-in-chief of the journal Software—Practice and Experience. As a member of the IAB, he participated in the formation of the Internet, and is considered a leading authority on TCP/IP and Internetworking. He is the author of 16 technical books that that have been translated into 14 languages, and are used around the world in industry and academia. Comer has been working with network processors for several years, and has reference platforms from three leading vendors in his lab at Purdue.